NaiveBayes Classifier
in Booststudy on Plus Education
NaiveBayes Classifier에 대한 요약과 구현을 진행한다. NaiveBayes Classifier에 대한 보다 자세한 설명은 여기에서 확인할 수 있다.
목차
1. NaiveBayes Classifier란?
위키백과 - 나이브 베이즈 분류에서 참고하였습니다.
- feature 사이의 독립을 가정하는 Bayes 정리를 적용한 확률 분류기의 일종
- 텍스트 분류에 사용되며, 문서를 여러 범주 (스팸, 정치 등) 중 하나로 판단하는 문제에 대하여 대중적인 방법으로 사용되어왔다.
- 자동 의료 진단 분야에서의 응용사례로서 적절한 전처리를 하게 되면, Support Vector Machine과도 충분한 경쟁력을 보일 수 있을 정도의 성능을 낸다고 한다.
2. NaiveBayes 요약 설명
- 분류 class가 c개 있다고 하고, 특정 문서 d가 주어졌을 때 그 문서가 어떤 클래스에 속할지를 분류한다.
- 여기서 특정 문서 d가 주어져 있을 때, c개의 각 클래스에 속할 지에 대한 확률분포는 다음과 같다.

- 여기서 P(d|c)는 특정 클래스 c가 고정되어 있을 때, 문서 d가 그 클래스에 나타날 확률을 나타내고, 이는 문서 d에서 나타나는 word들이 독립임을 가정하여 Bayes 정리를 적용할 수 있게된다. 즉, 다음과 같이 나타낼 수 있다.
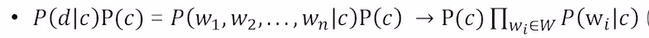
- 위의 식에 기반하여, 훈련하고자 하는(기존에 클래스를 알고있는) 문서를 바탕으로 각 단어들이 각 클래스에 속할 확률을 구해주고, 클래스를 알고 싶은 문서를 훈련된 분류기에 집어넣어 각 단어들이 각 클래스에 속할 확률을 바탕으로 최종 클래스를 예측하게 된다.
3. NaiveBayes Classifier 구현
3-1. 패키지 import
먼저, Terminal 환경에서 jdk를 설치해준다. konlpy의 Twitter(OKT) tokenizer를 사용하는데 있어서, jdk를 필요로하므로 이를 설치해준다. 설치가 되어있다면 넘어가도록 하자.
$sudo pat install default-jdk
필요로 하는 패키지를 설치 및 불러온다.
!pip install konlpy # 최초 한 번만 진행해준다.
from tqdm import tdqm
from konlpy import tag
from collections import defaultdict
import math
3-2. 데이터 전처리
학습 및 테스트 데이터 입력
train_data = [
"진짜 맛있어요. 강추강추",
"안가면 손해, 맛집이에요.",
"리뷰보고 갔는데 생각했던거와 다르네요.",
"최고에요! 다음에 또 오겠습니다.",
"주방 위생이 별로인거 같아요. 신경좀 쓰셔야 할듯..",
"중요한 날에 방문했는데 서비스가 좋아서 만족했습니다! 맛도 괜찮아요",
"생각보다 비싸요.. 가성비는 별로네요",
"재방문의사 100프로!!",
"서비스가 좋아요~ 친절하시네요!",
"청소는 하시나요... 매장이 조금 더럽네요,,",
"두번 다시 안갈듯.. 별로별로"]
train_labels = [1, 1, 0, 1, 0, 1, 0, 1, 1, 0, 0]
test_data = [
"정말 좋았어요! 또 가고 싶네요~",
"서비스가 별로였습니다.. 다시는 안갈듯",
"추천해드려요~ 꼭 가보세요!",
"위생상태가 정말 별로네요.."]
Tokenization
- tokenization을 통해, “안가면 손해, 맛집이에요.” -> [‘안’, ‘가면’, ‘손해’, ‘,’, ‘맛집’, ‘이에요’, ‘.’]와 같이 만들어준다.
tokenizer = tag.Okt() # Twitter(Okt) tokenizer를 사용하여 토큰화 진행
def make_tokenized(data) :
tokenized = []
for sent in tqdm(data) :
tokens = tokenizer.morphs(sent) # 형태소 단위로 문장 토큰화
tokenized.append(tokens)
return tokenized
train_tokenized = make_tokenized(train_data)
test_tokenized = make_tokenized(test_data)
Vocab 생성
- 가장 많이 등장한 토큰 순서대로 나열해주고 이를 index 매겨 vocab을 생성한다.
- vocab을 생성하는 방법은 다양하게 존재한다.
word_count = defaultdict(int) # 가장 많이 등장한 token 순서대로 dict형태로 나열한다.
for tokens in tqdm(train_tokenized) :
for token in tokens :
word_count[token] += 1
word_count = sorted(word_count.items(), key = lambda x: x[1], reverse = True)
word2idx = {} # 가장 많이 등장한 token 순서대로 index를 주어 Vocab 생성
for word, count in tqdm(word_count) :
if word not in word2idx :
word2idx[word] = len(word2idx)
3-3. 모델 구현
class NaiveBayesClassifier() :
def __init__(self, word2idx, k = 0.1) :
self.k = k # Regularization 기법으로 단어가 등장하지 않았을 때, 0이 되는 것을 막아준다.
self.word2idx = word2idx
self.priors = {}
self.likelihoods = {}
def train(self, train_tokenized, train_labels) : # P(w|c)와 P(c)를 구한다.
self.set_priors(train_labels)
self.set_likelihoods(train_tokenized, train_labels)
def inference(self, tokens) : # Inference 과정으로, class를 추측하고자 하는 문서의 tokenized된 형태를 입력하여 예측을 진행한다.
log_prob0 = 0.0
log_prob1 = 0.0
for token in tokens : # test tokens에서 각 token의 P(w|c)를 구하여 합한다.(log를 취했으므로 합한다.)
if token in self.likelihoods :
log_prob0 += math.log(self.likelihoods[token][0]) # 기존에는 log를 취하지 않고 곱한다.
log_prob1 += math.log(self.likelihoods[token][1])
log_prob0 += math.log(self.priors[0])
log_prob1 += math.log(self.priors[1])
if log_prob0 >= log_prob1 :
return 0
else :
return 1
def set_priors(self, train_labels) :
class_counts = defaultdict(int)
for label in tqdm(train_labels) : # 1, 0의 개수를 count
class_counts[label] += 1
for label, count in class_counts.items() : # label이 1 or 0일 확률을 계산
self.priors[label] = class_counts[label] / len(train_labels)
def set_likelihoods(self, train_tokenized, train_labels) : # train data에서의 각 단어별로 각각의 클래스에 들어갈 확률을 구한다.
token_dists = {} # 각 단어의 특정 class 조건 하에서의 등장 횟수
class_counts = defaultdict(int) # 특정 class에서 등장한 모든 단어의 등장 횟수
for i, label in enumerate(tqdm(train_labels)) :
count = 0
for token in train_tokenized[i] : # 각 문장에서의 token
if token in self.word2idx : # token이 vocab에 속해 있을 경우에만 고려
if token not in token_dists : # 각 token이 긍부정 문장에 얼마나 나타났는지에 대한 분포를 고려하기 위해 생성
token_dists[token] = {0:0, 1:0}
token_dists[token][label] += 1
count += 1
class_counts[label] += count # 특정 클래스에 등장한 단어의 개수만큼 label count
for token, dist in tqdm(token_dists.items()) :
if token not in self.likelihoods :
self.likelihoods[token] = {
0 : (token_dists[token][0] + self.k) / (class_counts[0] + len(self.word2idx) * self.k),
1 : (token_dists[token][1] + self.k) / (class_counts[1] + len(self.word2idx) * self.k)
}
3-4. 모델 학습 및 테스트
classifier = NaiveBayesClassifier(word2idx) # vocab을 사용하여 NaiveBayes분류기 정의
classifier.train(train_tokenized, train_labels) # 훈련
preds = []
for test_tokens in tqdm(test_tokenized) : # 예측
pred = classifier.inference(test_tokens)
preds.append(pred)
for data, pred in zip(test_data, preds) : # 최종 결과 출력
print('예측 문장 :', data)
print('예측 클래스 :', pred)
예측 문장 : 정말 좋았어요! 또 가고 싶네요~
예측 클래스 : 1
예측 문장 : 서비스가 별로였습니다.. 다시는 안갈듯
예측 클래스 : 0
예측 문장 : 추천해드려요~ 꼭 가보세요!
예측 클래스 : 1
예측 문장 : 위생상태가 정말 별로네요..
예측 클래스 : 0